

I was one of the few who did not comment on this METR graph, in which the AI capability curve shoots steeply upward, forming the desired hockey stick, exponential shape. Yet I have been saying for some time that there is no breakthrough in AI. How does this “hockey stick” fit in with this claim?
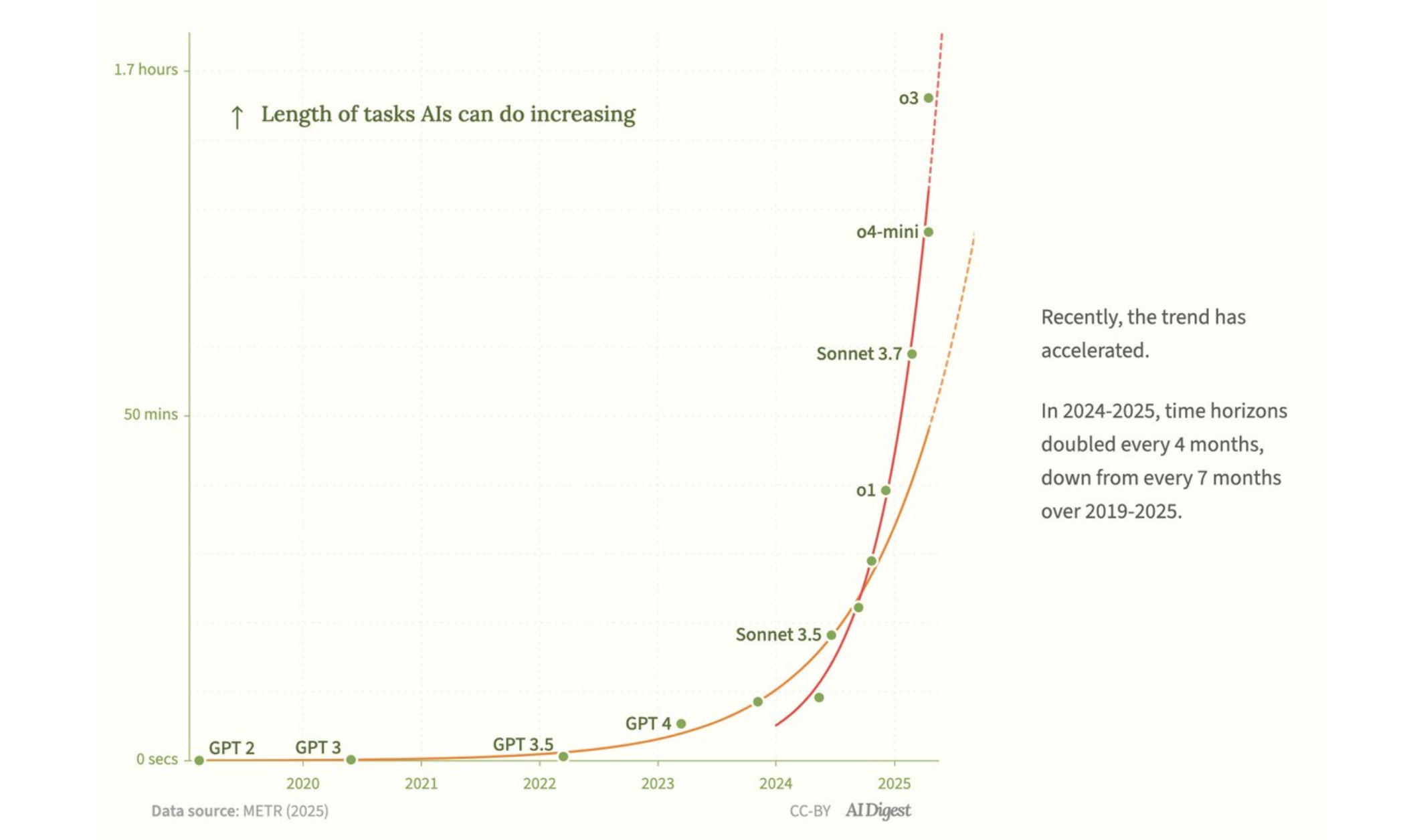
Here we need to go back to what the study means. First of all, this graph does not appear in the original METR study from March 2025; it is an update with new April models. The original graph ends with the old version of Sonnet 3.7. It was not until April that METR updated it on Twitter with the information that “o3 may be above the trend line,” from which AI Digest made this graph, which has been picked up by the Financial Times, major Chinese websites, and Czech media, interpreting it as “AI doubles its capabilities every seven months.” This would indicate a counterpart to Moore’s Law, which I have denied.
In fact, the METR report says no such thing. It provides some guidance, but that guidance cannot be taken out of context. In order for the report to measure complex tasks, it decided to simplify the problem by saying how long the longest tasks take for a given AI model with a 50% success rate. METR created a respectable set of tasks, most of which it did not publish to prevent them from being trained on. For those it did publish, it determined how long they took people to complete and measured whether a specific LLM achieved at least a 50% success rate in solving them. This is an interesting number, but it has several problems.
First of all, only software development was tested.
First, METR focused on tasks from the field of software development. Here is one very well-described task:
The task is to implement functions for processing payments and preventing duplicate transactions that arrive asynchronously from different time zones and currencies. Two payments must be paired based on fuzzy rules, such as the time difference between time zones and multi-stage currency conversions.
METR had this task programmed by an external contractor, who completed it (using libraries) in 23 hours and 30 minutes. This time was taken as a benchmark, and the task was assigned a complexity rating based on this time. METR did not have all tasks programmed by a large number of people; it only did this for shorter tasks and even for more complex ones, it only made estimates based on development methodology. The test determines whether, on average (over many—on average 5—attempts and tasks), the model achieves more than 50% success. This average is defined using a logistic model across tasks of varying lengths, not just a simple “half of the runs of a single task must pass” - but that is a detail for us.
However, the essence of the problem is not whether a person would have completed the task sooner or later, or how informative a single attempt by a programmer is for defining time in the METR methodology – that is essentially irrelevant, it just shifts the curve to the left or right.
It is not even certain that a task that METR evaluates as twice as long is actually twice as complex. That would affect the shape of the curve. METR solves this problem to some extent by having more tasks and using regression to plot the curve, so that tasks for which it would incorrectly estimate the time required by a human are averaged out and the curve does not suffer such distortion in the end.
The fundamental problem is that the tasks only relate to software development, for which today’s AI is trained in great detail. Software development is currently the largest domain of AI application, and most modern models compete with each other in terms of their usefulness in supporting software development. However, this is not the only group of tasks that people deal with. There are no mathematical tasks at all—for example, the traditional task of “how many letters r are there in the word strawberry” is still a tough nut to crack for many models. LLMs are not nearly as strong in logical or verbal, imaginative tasks, nor in legal tasks, and they cannot take a picture of clothing and convert it into a clothing pattern.
METR has therefore given up on the discipline in which AI is currently strongest – and has concluded that the length of tasks that AI can solve independently is increasing significantly. But let’s describe what METR is telling us in human terms:
METR found that after three years of concentrated effort by the largest and richest companies in the field, such as Google, Microsoft, Anthropic, and OpenAI, today’s best AI models, such as o3 and Sonnet 3.7, are capable of solving programming tasks with a complexity of around two hours. Tasks that would take a human programmer longer to complete are not yet solvable (*). In other words, the task of replacing programmers with AI, which has been a major concern for these companies (as it accounts for a large part of their costs), is still only solved at a very junior level. Two-hour tasks are not that impressive (**), which means that such a programmer’s boss has to stop by four times a day to check on their work.
I had to methodically give it one star because tasks lasting two hours are solved by the o3 model with a 50% probability, which in fact means that you run it about three times and it will probably work, which is not such a problem considering that it will only take a few minutes to solve.
I have to give the second star for the quality of the assignment. METR provides very precise task assignments that don’t leave much room for research. You just sit down and code, you don’t have to research anything, everything is clearly specified. This is not a very common way of assigning work in the Czech Republic.
We didn’t find out anything about how AI could help you in other professions. No tasks were created for this, and let’s be honest, in professions other than software development, there is no such concentrated involvement on the part of companies.
The human world is multifaceted. You can be a great programmer, but as a person, you’re worthless. How good you are as a programmer doesn’t say anything about how well you can solve other types of tasks or how much you can develop yourself further.
So what can we really conclude from the METR test?
There is a strong correlation between the relative ranking of models – it is a well-established and proven ranking of models for solving software tasks.
The complexity or rather the length of the tasks that a model can handle with a 50% probability is more indicative – the complexity depends on the accuracy of the initial estimate.
The claim that AI is improving at solving development tasks, with doubling occurring at an ever faster rate, is highly debatable. METR plotted how long each model can handle human tasks with 50% success in a log graph and drew a straight line through these points. The slope shows that the value on the Y-axis doubles on average every 212 days. However, there are very few measurements and they are subject to considerable error. Until you have more measurements (and less error), you cannot say with certainty that growth has accelerated. This is exactly the situation METR is in: the trend looks exponential; the last two points (o3 and o4-mini) indicate a possible acceleration, but due to ±19% “blurring” of the data, this is not yet statistically significant.
It is also impossible to draw any conclusions about whether the LLM in question is a viable replacement for a programmer, as the data does not record how long it took to program the task using AI, so there is no cost comparison.
And to derive statements such as “AI can handle all hourly cognitive tasks within X months” from the graph is completely off the mark. The study covers almost exclusively software engineering. Multimodal, social, or physically oriented tasks are missing. Any extrapolation beyond SW is therefore completely unjustified.
I am not alone in my skepticism about the general interpretation of the otherwise precise METR report. In addition to Nature magazine, Gary Marcus and Cole Wyeth have expressed similar concerns. Steve Newman also notes that the last two points (o3 and o4-mini) are above the trend but within the noise interval, so we need to wait for confirmation of acceleration. Zvi Mowshowitz (blog Straight Line on a Graph) points out that extrapolation to monthly tasks assumes a constant exponent, which is rare in the history of engineering trends. He also points to the fact that exponential growth can slow down once the “low-hanging fruit” has been picked. To get the broadest possible picture of the discussion, I recommend starting with Marcus (he’s sharp but readable), then Steve Newman and his sober technical details…
So AGI and Moore’s Law for AI are not yet confirmed. And in my opinion, they are not even in sight.
If you want my prediction for the next ten years, LLM will turn out similarly to humans. A few models will achieve high A-IQ and, at great expense, will be able to do very advanced things, but they will have their limits and quirks—similar to mental defects and depression in genius people. For example, a high degree of hallucination (o3 has it!). Cheap and less intelligent models will be useful for routine tasks. We will spend the next ten years primarily connecting individual software, LLM, agents, and the human world.
