

You’ve probably heard about it. Chinese company Deepseek released its new AI models, and a trillion dollars was wiped off the US tech stock market in an instant. Shares in Nvidia and Broadcom, two publicly traded companies dependent on the success of AI chip sales, fell 17 percent in one day (on Monday) and did not recover on Tuesday, although they appear to be stabilizing.
Let’s say a few words about this:
-
The rule of no sudden moves applies. If you have shares, don’t sell them yet.
-
I have rewritten this article three times since Saturday and decided to make it just a very short teaser. The situation has not yet settled down and it is not entirely clear what is true, what is coincidence and what is a trend.
What actually happened? Before Christmas, Chinese company Deepseek released the second generation of its AI LLM. That was already a big deal. Now it has released another one and made a web version of its model available for download as open source. And that’s what caused the market to explode, with everyone trying to recover and figure out what it means and how it changes everything…
So let’s take a quick look at the timeline with comments:
December 2024
- DeepSeek releases the DeepSeek-V3 model
- The model uses a “mixture of experts” architecture for more efficient use of parameters
- Reaction: The model is hailed as a significant advance in open-source AI (ITOnline). But otherwise, it’s quiet for now.
January 20, 2025
- DeepSeek releases the DeepSeek-R1 model
- R1 is focused on advanced reasoning and solving complex tasks
- Reaction:
- The model is hailed as a breakthrough, comparable to OpenAI o1
- The DeepSeek app becomes the most downloaded app in the App Store (TechCrunch)
January 24, 2025
-
It emerges that DeepSeek allegedly developed R1 for only $6 million (this is somewhat misleading, as this was the cost of the processor time for training alone, not including labor, testing, debugging, etc.)
- Reaction:
- Some experts express doubts about the veracity of the claim
- Investors concerned about possible disruption of US tech companies’ dominance (Livescience.com)
January 26-27
- Dramatic drop in tech stocks
- Nvidia loses 17% of its value, representing a record one-day loss of $593 billion
- Overall, approximately $1 trillion in value is wiped off the market (Evrimagaci)
January 27, 2025
- DeepSeek releases Janus-Pro-7B model for image generation
- The model reportedly outperforms DALL-E 3 and Stable Diffusion in some benchmarks
- Reaction:
- Another shock for the market and competition
- Growing recognition of DeepSeek as a serious competitor in the global AI race (ObserverVoice)
January 28, 2025
- Ongoing discussion about the impact of DeepSeek on the global AI market
- Some experts urge caution in evaluating DeepSeek’s claims
- Growing debate on the future of AI development and global competition in this field (Mickryan, FinancialExpress
What is the main surprise, the snag, and the Sputnik effect that has knocked America (and especially the US technology markets) off its feet?
On the one hand, there are the costs. On the other hand, there is the enormous quality of the output.
Costs: how did they do it for that money?
Perhaps the most remarkable thing about DeepSeek-V3, however, was its price. DeepSeek said that V3 was trained for approximately two months on a cluster of 2,048 graphics processors, representing a total of 2.8 million GPU hours. Assuming that GPU rental costs $2 per hour, that comes out to approximately $5.6 million in training costs.
For comparison, Meta trained its Llama 3 models on a cluster of 16,000 GPUs. Industry experts estimate that training the largest Llama 3.1 model, which has 405 billion parameters, took approximately 30 million hours on GPUs. In other words, training the Llama model required approximately ten times more computing power than training the V3 model. And it is not clear that Llama is a better model than V3.
Sure, the Deepseek document doesn’t say this explicitly, and it’s very likely that it actually cost a few pennies more for various tests and work around it, but the tenfold drop in price is staggering. This cannot be attributed solely to the “Chinese price” factor, i.e., lower costs in China; there are several technological breakthroughs behind it. There are a number of advanced algorithms, such as Multi-head Latent Attention (MLA). This allows for more efficient inference by compressing key values into a latent vector. In layman’s terms, MLA reduces memory requirements during text generation, which translates into significantly reduced hardware requirements. But the masterstroke was the way the team circumvented the embargo on the export of high-end Nvidia H100 processors. Instead, training was carried out on the slower H800 version with slower memory. So DeepSeek wrote its own memory drivers, turning a handicap into an advantage.
DeepSeek also uses optimized CUDA kernels to increase training and inference speeds. These kernels are specifically designed and modified for the needs of DeepSeek models to maximize GPU computing power.
Deepseek had a whole series of such approaches and improvements behind it, which is what caused the technological panic. Simply put, if you only need two thousand Nvidia processors to train the most advanced AI, who is going to buy the piles of processors that Nvidia needs to sell to meet shareholder expectations? That was the reason why Nvidia and Broadcom shares plummeted on Monday, wiping $1 trillion off the market value of US companies.
And API prices for customers?
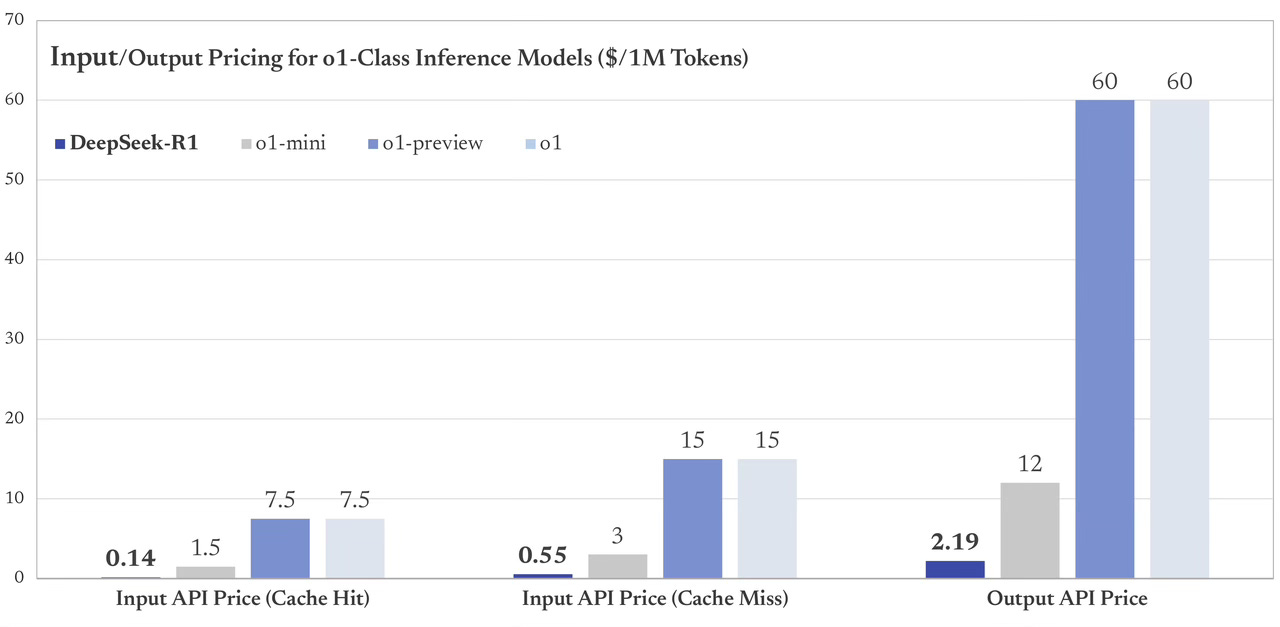
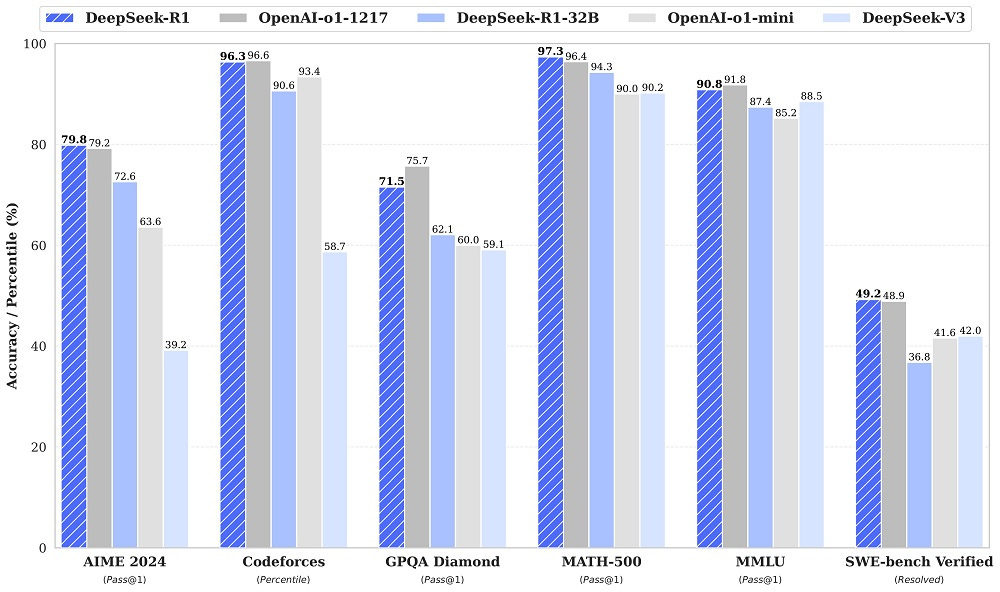
What about quality?
Simply put, Deepseek-R1 outputs are more or less on par with the o1 model. Feel free to skip the graph if you trust me, but let’s comment on it anyway. Let’s take a look at the tests that are considered extremely difficult: MATH 500 (which is 500 randomly selected tasks from the entire test set), AIME 2024 (super difficult competitive math problems), Codeforces (competitive code introduced in o3), and SWE-bench Verified (Improved distribution of the OpenAI dataset). Beating GPT-4o and Claude 3.5 together, and by such a wide margin, is rare. And yes, Deepseek works well in Czech, although I think the fluency of the text is better in both o1 and Claude, but nothing you would need to dwell on.
What next?
I will continue to monitor the situation and plan to write a more comprehensive article about Deepseek, where we will analyze it in detail. For us, however, the following findings are essential – I will summarize them briefly in bullet points:
- In AI, everything is still up for grabs. The Deepseek team consists of around 150 people, the vast majority of whom are young people who completed their doctorates at prestigious Chinese universities two years ago. And they shook the world.
- There is still room for cleverness and a motivated team in AI.
- Price is a key factor, and Deepseek has slashed the price of AI models in China to a third of the previous price and will shake up prices elsewhere in a similar way. Their API runs on OpenAI, so there is little to prevent switching to them and using high-quality AI at a lower price.
- But it’s still China: data goes to China, believe who you want, but Chinese laws are clear and unforgiving, as are the licensing terms, which say they can do anything.
- So far, it doesn’t look like the mobile app is necessarily sending more than the maximum amount of data to China, but still: if you want to experiment on your mobile, do it via the web. In addition, Deepseek currently has capacity issues and overloaded servers, so you won’t get as good an impression of it as it actually is.
- It is clear that much of the work today is in the direction of agents, i.e., the exchange of data between LLM and the outside world. Deepseek has no interfaces or connections to the outside world except for web access. It also lacks support modes such as Canvas or Artifact.
One important message remains for the EU: trying to regulate AI was… an interesting, bold, even revolutionary idea. But it will have to change. Deepseek is open source, and it can be assumed that everyone who needs open source will switch to it because of its qualities. However, they will not be able to comply with EU regulations regarding the clear definition of training data. Deepseek has put something into its AI, it’s not very clear what (part of it was trained against OpenAI’s AI, which its chat innocently admits) – and how this could be used to create a reliable definition of the origin of the content is not clear to me. So, however justified the reason for the regulation may be, everyone will probably accept that it works and works well, never mind where the data came from. Just don’t ask about it in China’s Tiananmen Square, but on a downloaded model, you can add that it’s calm.
Deepseek r1 is an impressive model, especially considering what they are able to offer for the price. Of course, we will deliver much better models, and it’s also legitimately encouraging to have a new competitor! We’ll release some versions. But above all, we are excited to continue our research plan and believe that more computing power is now more important than ever to succeed in our mission. The world will want to use a lot of AI and will be truly amazed by the next generation of models. We look forward to bringing AGI and more to all of you. - January 28, 2025, tweet by Sam Altman, CEO of OpenAI
